収束の違いを情報幾何で見る
Series
情報幾何から検定へ前の記事では、推定と検定の違いを見ました。
推定は、データに合う確率分布を選ぶことです。
検定は、帰無仮説のもとでデータがどれくらい珍しいかを見ることです。
ここから先で尤度比検定や Wilks の定理へ進む前に、ひとつ整理しておきたいことがあります。
それが「収束」です。
統計では、収束という言葉が何度も出てきます。
- 推定量が本当の値へ収束する。
- 推定量の分布が正規分布へ収束する。
- 尤度比統計量が 分布へ収束する。
- 最適化アルゴリズムが解へ収束する。
どれも「収束」と呼びますが、同じ意味ではありません。
この記事では、収束の違いを情報幾何学の言葉で整理します。
収束は「近づく」だけでは足りない
収束を雑に言えば、「何かが何かに近づくこと」です。
でも統計では、何が近づくのかをはっきり分ける必要があります。
たとえば、コイン投げを考えます。
表が出る確率を とします。
コインを 回投げて、表の割合を
とします。
が大きくなると、 は本当の に近づきそうです。
これは直感的です。
でも、次の 2 つは違う主張です。
- の値そのものが に近づく。
- の揺れ方が、ある分布に近づく。
前者は、推定値の収束です。
後者は、分布の収束です。
この違いを混ぜると、検定や信頼区間の読み方がわかりにくくなります。
一致性は「点として近づく」
まず、一致性から見ます。
推定量 が本当のパラメータ に近づくとき、その推定量は一致性を持つと言います。
コインの例なら、
です。
直感的には、たくさん投げれば、表の割合は本当の表確率 に近づきます。
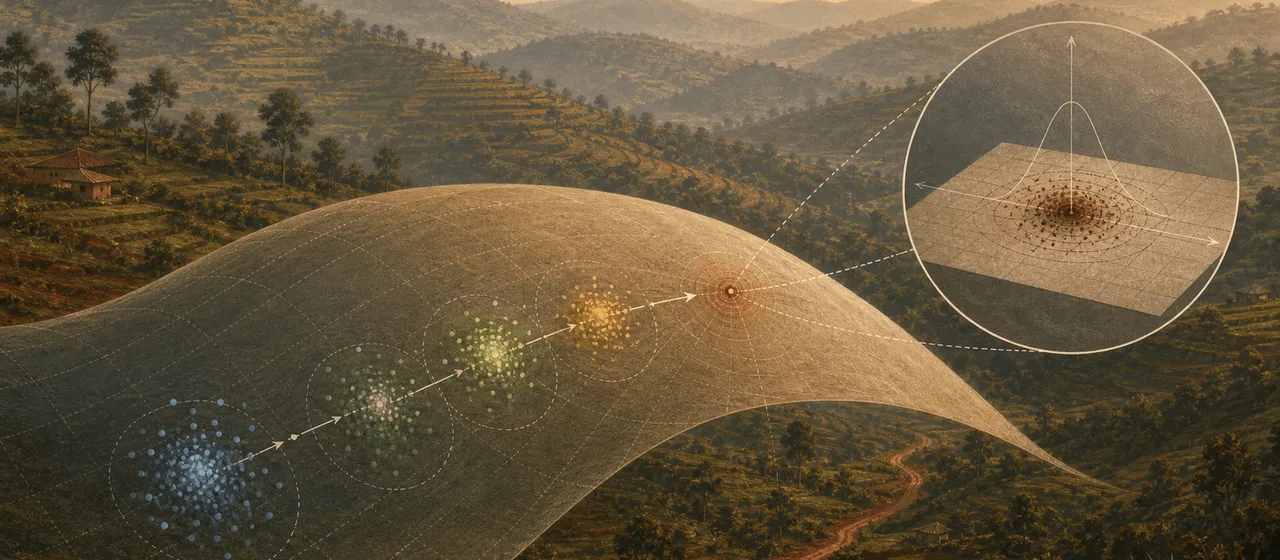
情報幾何学の言葉で言えば、これは「推定された点が、確率分布の多様体上で真の点へ近づく」ということです。
真の分布を点 とします。
推定された分布を点 とします。
一致性は、
という絵で見られます。
ただし、ここで「近い」とは何で測るのでしょうか。
パラメータの座標で近いのか。
確率分布として近いのか。
KL divergence で近いのか。
Fisher 計量で局所的に近いのか。
ここで情報幾何が効いてきます。
座標の数字だけで見ると、近さの意味が座標の取り方に依存します。
一方、情報幾何では、確率分布としての近さを見たいので、Fisher 計量や KL divergence が自然に出てきます。
分布として近いことと、座標として近いこと
同じ確率分布を、別の座標で表せることがあります。
Bernoulli 分布なら、表の確率 で表すこともできます。
自然パラメータ
で表すこともできます。
の座標で少し動くことと、 の座標で少し動くことは、同じ見え方ではありません。
特に が 0 や 1 に近いところでは、少しの変化が分布として大きな意味を持ちます。
だから、単に
を見るだけでは足りない場面があります。
分布としてどれくらい違うかを見たいなら、KL divergence や Fisher 計量で見たほうが自然です。
確率収束は「外れる確率が小さくなる」
統計でよく出てくる収束に、確率収束があります。
これは、推定量が真の値から大きく外れる確率が小さくなる、という意味です。
式で書くと、
です。
これは「 は確率的に へ収束する」と読みます。
意味としては、任意の小さな幅 に対して、
ということです。
言葉にすると、
「真の値から 以上離れる確率が、データ数とともに 0 に近づく」
です。
情報幾何学の言葉では、推定点 が真の点 の近くに入る確率が高くなる、と見られます。
点そのものが固定されて動くのではなく、データによってランダムに動く点が、だんだん真の点の近くに集まってくるイメージです。
分布収束は「揺れ方が近づく」
次に分布収束です。
分布収束は、値そのものがある値に近づくというより、ランダムな量の分布の形がある分布に近づくことです。
式では、
と書きます。
これは「 は分布として に収束する」と読みます。
たとえば、推定量 そのものは真の値 に近づきます。
でも、そのままだと揺れがどんどん小さくなって、最終的には一点に潰れていきます。
そこで、揺れを見たいときは、差を 倍します。
この量は、データ数が増えてもほどよい大きさの揺れとして残ります。
多くの正則なモデルでは、この量が正規分布に近づきます。
√n 収束は「局所的に拡大して見る」
推定量が真の値に近づくなら、差
は 0 に近づきます。
でも、そのままでは揺れが消えてしまいます。
そこで 倍して、真の点のまわりを拡大します。
これは、顕微鏡で真の点の近くを拡大して見るようなものです。
情報幾何学では、この拡大後の世界は接空間として見ると自然です。
真の分布 の近くを拡大すると、曲がった多様体も、ほぼ平らな接空間のように見えます。
つまり、推定量の揺れは、真の点の接空間の中のベクトルとして見られます。
ここで Fisher 計量が、その接空間上のものさしになります。
n が増えると推定値の揺れは狭くなる
同じ p = 0.5 の推定でも、サンプルサイズが増えると標本分布は 1 / sqrt(n) のスケールで細くなります。
sqrt(n) と局所距離を動かす
値を動かして、検定統計量・p 値・標準誤差・情報量の見え方を確認できます。
漸近正規性は「接空間で正規分布になる」
多くの正則な統計モデルでは、最尤推定量は漸近正規性を持ちます。
ざっくり書くと、
これは何を言っているのでしょうか。
まず、 は に近づきます。
ただし、近づき方には揺れがあります。
その揺れを 倍して拡大すると、正規分布のような形に近づきます。
そして、その正規分布の広がり方を決めるのが Fisher 情報行列です。
Fisher 情報が大きい方向では、分布がパラメータ変化に敏感です。少し動かすだけでデータの出方が変わるので、推定しやすい方向です。
Fisher 情報が小さい方向では、分布が変化に鈍いです。データから見分けにくいので、推定の揺れが大きくなります。
つまり、Fisher 計量は「どの方向が推定しやすいか」も表しています。
なぜ正規分布が出るのか
ここは直感で十分です。
最尤推定量は、対数尤度が一番大きい点です。
真の値の近くで対数尤度を見ると、なめらかな山の頂上のようになっています。
頂上の近くを拡大すると、山の形は二次関数で近似できます。
二次関数の曲がり具合が Fisher 情報です。
一方、データから来るランダムな揺れは、たくさんの小さなランダムな影響の合計です。
たくさんの小さな揺れの合計は、中心極限定理によって正規分布に近づきます。
その結果、推定量の局所的な揺れも正規分布に近づきます。
χ² 収束は「正規ベクトルの長さの 2 乗」
尤度比検定では、統計量が 分布に近づくことがあります。
これは分布収束の話です。
推定量そのものが 分布に近づくのではありません。
尤度比統計量という、データから作った量の分布が、帰無仮説のもとで 分布に近づきます。
情報幾何学の言葉で見ると、これはかなり自然です。
真の点の近くを で拡大すると、統計モデルの多様体は接空間のように見えます。
その接空間で、推定量の揺れは正規分布のように見えます。
正規分布するベクトルの長さの 2 乗を測ると、 分布が出ます。
そして、その長さを測るものさしが Fisher 計量です。
つまり、尤度比検定の 近似は、
「真の点のまわりを拡大し、Fisher 計量で測った正規的な揺れの長さを見る」
という絵で理解できます。
収束先が点なのか、分布なのか
ここまでをまとめると、収束には少なくとも 2 つの見方があります。
| 収束の話 | 何が近づくか | 情報幾何での見方 |
|---|---|---|
| 一致性 | 推定点が真の点へ近づく | 統計多様体上の点が真の点へ集まる |
| 確率収束 | 真の点から外れる確率が小さくなる | 真の点の近傍に入る確率が高くなる |
| 分布収束 | ランダムな量の揺れ方が近づく | 接空間上の揺れの分布が近づく |
| 漸近正規性 | 倍した誤差が正規分布へ近づく | 真の点の接空間で正規的に揺れる |
| 近似 | 検定統計量の分布が へ近づく | Fisher 計量で測った長さの 2 乗を見る |
この表のポイントは、収束先が違うことです。
一致性では、点へ近づきます。
分布収束では、揺れ方の分布へ近づきます。
漸近正規性では、真の点のまわりを拡大した接空間で、正規分布へ近づきます。
尤度比検定では、その正規的な揺れを Fisher 計量で測った 2 乗が、 分布へ近づきます。
統計的な収束と最適化の収束は違う
もうひとつ、混乱しやすい違いがあります。
統計的な収束と、最適化の収束です。
統計的な収束は、データ数 が増えたときの話です。
たとえば、 が増えると推定量が真の値へ近づく、という話です。
一方、最適化の収束は、アルゴリズムの反復回数が増えたときの話です。
たとえば、勾配降下法を何ステップも回すと、損失の小さい点へ近づく、という話です。
この 2 つは別です。
データが少なければ、最適化を完全に収束させても、真の分布に近いとは限りません。
逆に、データが十分多くても、最適化が途中で止まれば、最尤推定量には到達していません。
情報幾何学では、最適化の収束も地図の上の移動として見られます。
勾配降下法は、損失を下げるベクトル場に沿って進む方法です。
natural gradient は、Fisher 計量で見た自然な方向へ進む方法です。
統計的な収束は、データ数が増えたときに、推定点やその揺れがどう変わるかを見る話です。
最適化の収束は、同じデータのもとで、アルゴリズムがどの点へ近づくかを見る話です。
どちらも確率分布の地図の上で起きますが、動かしているものが違います。
非正則な場合は収束の形が変わる
ここまでは、条件がよい正則なモデルを暗黙に考えていました。
でも、いつもきれいに で正規分布へ収束するとは限りません。
たとえば、パラメータが境界にある場合があります。
分散は 0 未満にはなれません。混合モデルの重みも 0 未満にはなれません。
このように、真の値が境界にあると、真の点のまわりを拡大しても、きれいな平面ではなく半空間のように見えることがあります。
また、モデルが特異な場合もあります。
ニューラルネットワークや混合モデルでは、別々のパラメータが同じ分布を表すことがあります。こうなると、パラメータ空間の見かけと、分布の空間の形がずれます。
このような場合、通常の漸近正規性や Wilks の定理がそのまま使えないことがあります。
この話は、検定ではかなり重要です。
尤度比統計量が 分布に近づくという話は、正則性に支えられています。
正則性が崩れると、収束先の分布も変わることがあります。
選択後推論では、収束の基準も変わる
Selective Inference に進むと、さらに別の注意が出てきます。
データを見てからモデルや仮説を選んだ場合、同じデータでそのまま検定すると、通常の標本分布とは違う分布を見なければならないことがあります。
たとえば、たくさんの特徴量を見て、その中で一番よさそうなものだけを選ぶとします。
そのあとで「この特徴量は有意か」と検定すると、最初からその特徴量だけを見ていた場合とは状況が違います。
なぜなら、「よさそうに見えたから選んだ」という条件が入っているからです。
このとき、収束先の分布や p 値の基準も、選択を条件にしたものへ変わります。
情報幾何学の言葉で言えば、ただモデル多様体全体を見るのではなく、「選択によって切り取られた領域」の中で揺れ方を見る必要があります。
ここが Selective Inference の入口です。
今日のまとめ
収束には種類があります。
一致性は、推定点が真の点へ近づく話です。
確率収束は、真の点から大きく外れる確率が小さくなる話です。
分布収束は、ランダムな量の揺れ方がある分布へ近づく話です。
漸近正規性は、 倍した推定誤差が、真の点の接空間で正規分布のように見える話です。
尤度比検定の 近似は、その正規的な揺れを Fisher 計量で測った長さの 2 乗として見ると理解しやすくなります。
統計的な収束と最適化の収束も別です。前者はデータ数を増やす話で、後者はアルゴリズムの反復回数を増やす話です。
この違いを押さえておくと、尤度比検定で Wilks の定理や 近似が出てきても、何がどこへ収束しているのかを見失いにくくなります。
次に読む
この記事の前提や続きを確認したい場合は、関連する記事と用語集をあわせて読むと全体像を追いやすくなります。